
Czasami jedno zdanie usłyszane na szkoleniu może otworzyć przed nami zupełnie nowy świat technologiczny. Tak było w moim przypadku z terminem „fuzzy matching” – jeśli dobrze pamiętam, po raz pierwszy usłyszałem go podczas szkolenia z SQL Server. Nazwa brzmiała na tyle intrygująco, że zapadła mi w pamięci i postanowiłem sprawdzić, co się za nią kryje.
Pierwsze, na co natrafiłem w materiałach i dokumentacji, to algorytm Soundex – i właśnie od niego zacząłem zgłębiać temat podobieństwa tekstów. W tym artykule chciałbym najpierw opowiedzieć o fuzzy matching, a następnie przejść do Soundex, który jest jednym z najprostszych, ale i najczęściej spotykanych podejść do wyszukiwania fonetycznego.
Czym jest fuzzy matching?
Fuzzy matching, czyli rozmyte dopasowywanie, to technika porównywania tekstów, która pozwala znajdować podobieństwa między stringami nawet wtedy, gdy nie są one identyczne. W przeciwieństwie do tradycyjnego porównywania dokładnego (exact match), fuzzy matching toleruje różnice wynikające z literówek, różnej pisowni, skrótów czy nawet błędów w danych.
Wyobraź sobie sytuację, w której w bazie danych masz wpisy: „Jan Kowalski”, „Jan Kowalsky” i „J. Kowalski”. Tradycyjne zapytanie SQL z operatorem = traktowałoby te wpisy jako całkowicie różne. Fuzzy matching pozwala rozpoznać, że prawdopodobnie odnoszą się do tej samej osoby i ocenić stopień ich podobieństwa.
Algorytmy fuzzy matching działają na różnych zasadach – niektóre analizują odległość edycyjną między tekstami (ile operacji potrzeba, żeby zmienić jeden tekst w drugi), inne skupiają się na podobieństwie fonetycznym (jak słowa brzmią), a jeszcze inne wykorzystują analizę n-gramów czy tokeny.
Praktyczne zastosowania to między innymi:
- Deduplikacja danych w bazach
- Wyszukiwarki tolerujące błędy pisowni
- Systemy CRM łączące duplikaty klientów
- Analiza sentimentu w mediach społecznościowych
- Systemy rekomendacyjne
SOUNDEX
Algorytm Soundex został opracowany, aby ułatwić wyszukiwanie słów brzmiących podobnie, nawet jeśli zapis różni się literowo. Jego działanie sprowadza się do kilku kroków. Na początku zachowywana jest pierwsza litera wyrazu – to ona zawsze otwiera kod. Następnie z dalszej części słowa usuwane są wszystkie samogłoski oraz litery h i w, ponieważ nie mają one dużego znaczenia fonetycznego. Pozostałe spółgłoski otrzymują cyfrowe oznaczenia od 1 do 6, przy czym każda grupa liter o podobnym brzmieniu dzieli ten sam numer (np. b, f, p, v → 1, c, g, j, k, q, s, x, z → 2, d, t → 3 itd.).
Jeśli w wyrazie wystąpią obok siebie litery zakodowane tą samą cyfrą, są one traktowane jako jeden dźwięk – zapisuje się więc tylko jedną cyfrę. Podobna zasada działa, gdy takie litery są oddzielone h lub w. Wyjątkiem są sytuacje, gdy pomiędzy nimi pojawi się samogłoska – wtedy każda z liter jest kodowana osobno, aby zachować różnice w brzmieniu.
Ostateczny wynik zawsze ma cztery znaki: pierwsza litera + trzy cyfry. Jeśli kod jest za krótki, dodawane są zera (np. Gauss → G200), a jeśli za długi – obcina się go do wymaganej długości (np. Bangalore → B524). Dzięki temu porównywanie kodów jest szybkie i spójne.
Teraz, gdy już wiemy, jak działa algorytm Soundex w swojej klasycznej, angielskiej wersji, przejdźmy do przykładów. Ja skupię się przede wszystkim na zastosowaniach w języku polskim, ponieważ to właśnie z takimi danymi pracuję najczęściej i tam też pojawia się najwięcej wyzwań związanych z dopasowywaniem fonetycznym.
Najpierw stwórzmy sobie przykładową tabelę z danymi:
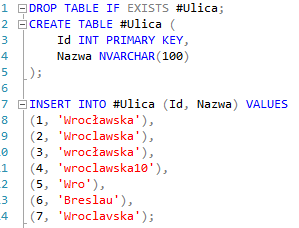
W tabeli mamy 7 różnych wpisów odnoszących się potencjalnie do tej samej ulicy. To częsty problem w bazach adresowych – dane są wprowadzane przez różne osoby, często bez zachowania spójnych standardów. W efekcie ta sama nazwa może występować w kilku wariantach: z polskimi znakami i bez nich, z dodatkowymi cyframi, skrótami albo nawet historycznymi odpowiednikami (jak „Breslau”). Choć dla człowieka oczywiste jest, że wszystkie rekordy mogą oznaczać tę samą ulicę, to w SQL użycie warunku WHERE Ulica = 'Wrocławska' zwróci tylko jeden dokładnie dopasowany wpis, a pozostałe zostaną pominięte.
Jeśli spróbujemy wykorzystać funkcję SOUNDEX w SQL i porównamy nasze dane z hasłem „Wrocławska”, to zapytanie zwróci tylko dwa rekordy:
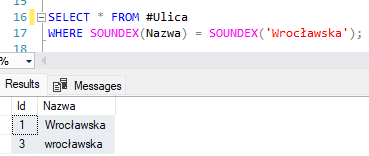
Wynik ten pokazuje, że algorytm faktycznie znajduje pewne podobieństwa, ale działa zgodnie z regułami fonetyki języka angielskiego. Dlatego ignoruje wpisy takie jak „Wroclawska” (bez polskich znaków), „Wroclavska” czy „Breslau”. W praktyce oznacza to, że w polskich danych adresowych SOUNDEX ma ograniczoną skuteczność i często nie wystarcza do wyłapania wszystkich wariantów tego samego słowa.
Jak sprawdzimy wyniki dla SOUNDEX to mamy potwierdzenie:
Aby sprawdzić, czy można uzyskać lepsze rezultaty niż przy samym SOUNDEX, możemy sięgnąć po funkcję DIFFERENCE. Działa ona w oparciu o kody Soundex, ale zamiast prostego porównania, zwraca miarę podobieństwa w skali od 0 do 4:
0 – brak wspólnych znaków w kodach Soundex.
1 – tylko pierwszy znak (litera) jest zgodny.
2 – pierwszy znak + jedna cyfra są zgodne.
3 – pierwszy znak + dwie cyfry są zgodne.
4 – pełna zgodność wszystkich 4 znaków Soundex.
Dzięki temu możemy posortować dane według tego, jak „blisko” znajdują się względem naszego wzorca.
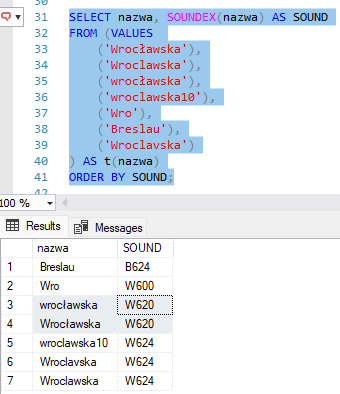
Możemy to zobaczyć na przykładzie:
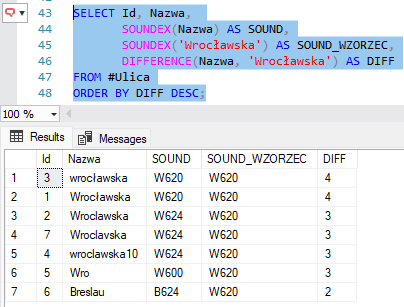
W praktyce, przy pracy z danymi adresowymi, najczęściej interesuje nas poziom 3 i 4, bo one dają realną szansę na to, że mamy do czynienia z tym samym bytem (np. nazwą ulicy). Poziom 2 może być jeszcze rozważany w analizach „luźnych” (np. wyszukiwanie podobnych nazwisk), ale przy adresach zwykle generuje za dużo fałszywych dopasowań.
Warto więc przyjąć zasadę:
DIFFERENCE >= 3 – do dalszego rozpatrzenia jako potencjalnie ta sama nazwa,
DIFFERENCE = 4 – pewne dopasowanie.
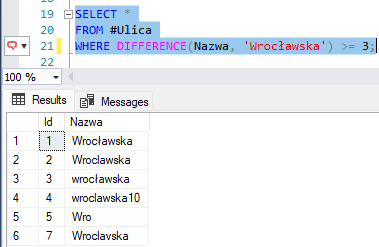
Trzeba jednak pamiętać, że funkcje SOUNDEX i DIFFERENCE zostały zaprojektowane z myślą o fonetyce języka angielskiego. W przypadku języka polskiego ich skuteczność jest ograniczona.
Przykładowo:
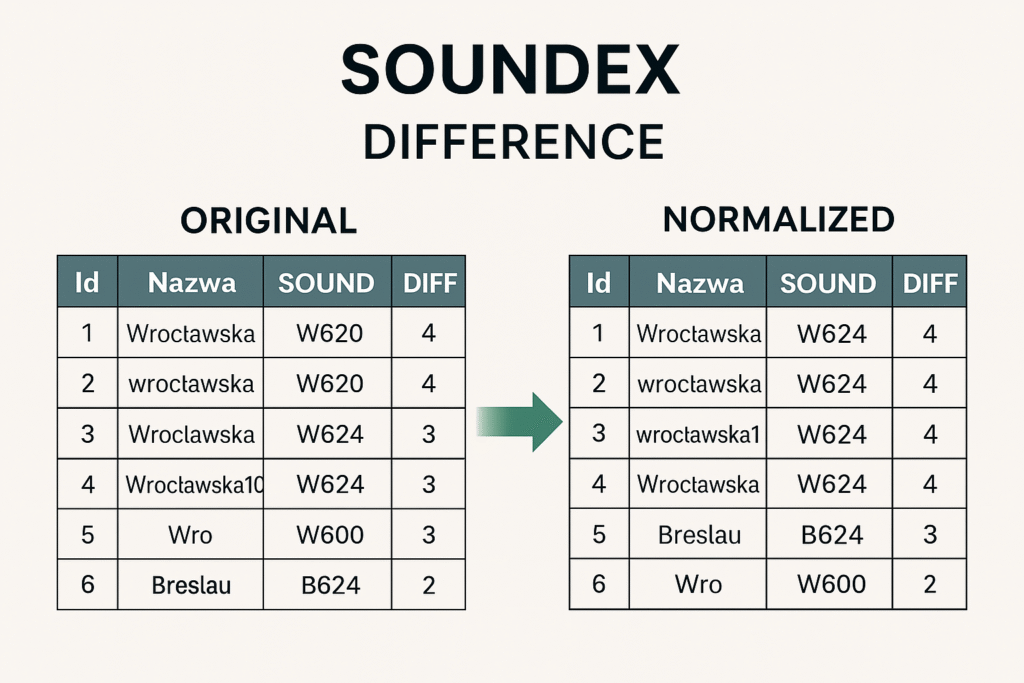
Zapis „Wroclawska” i „Wrocławska” dostają wynik 3, choć z punktu widzenia użytkownika to praktycznie to samo.
Krótkie formy, jak „Wro”, także potrafią uzyskać 3, mimo że wcale nie są równoważne całej nazwie ulicy.
Zupełnie inne słowa, np. „Breslau” (niemiecka nazwa Wrocławia), mogą osiągnąć 2, co już zaczyna generować niejednoznaczność.
Dlatego w polskich bazach danych przyjęcie progu DIFFERENCE >= 3 wymaga ostrożności. Warto traktować to raczej jako wstępny filtr kandydatów, a nie ostateczne kryterium równości. W praktyce często konieczne jest uzupełnienie porównań o dodatkowe metody – np. fuzzy matching (Levenshtein, Damerau-Levenshtein) czy własne reguły biznesowe (np. usuwanie końcówek „-ska”, normalizacja znaków diakrytycznych).
Jak widać, SOUNDEX i DIFFERENCE w czystej postaci mają swoje ograniczenia w języku polskim, dlatego warto dodać krok pośredni – normalizację danych. Najprostsza normalizacja polega na zamianie polskich znaków diakrytycznych (ą, ę, ł, ó itd.) na ich „zwykłe” odpowiedniki. Dzięki temu porównania stają się bardziej spójne.
Przykładowo, w zapytaniu:
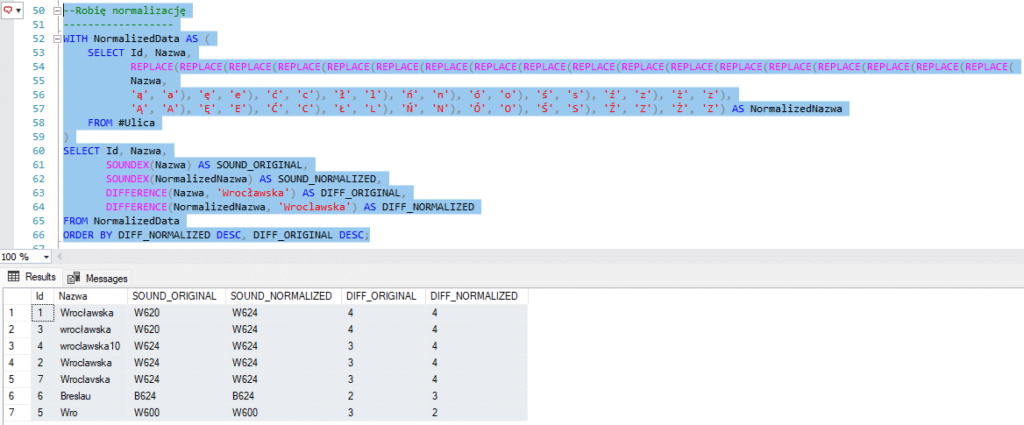
Dzięki normalizacji widzimy wyraźną poprawę wyników:
Nazwy różniące się tylko polskimi znakami („Wrocławska” vs „Wroclawska”) uzyskują pełne dopasowanie (DIFFERENCE = 4).
Warianty takie jak „wroclawska10” czy „Wroclavska” również przesunęły się do wyższej kategorii podobieństwa.
Nawet „Breslau” – historyczna niemiecka nazwa Wrocławia – po normalizacji osiągnęła wynik 3, czyli sygnał, że mimo innego zapisu istnieje pewne podobieństwo fonetyczne.
To pokazuje, że już sama normalizacja (bez bardziej zaawansowanych algorytmów) znacząco zwiększa skuteczność wyszukiwania podobnych nazw.
W tym tekście przyjrzeliśmy się temu, jak w SQL Server można podejść do porównywania danych tekstowych, które często w praktyce nie są wpisywane w sposób jednolity. Funkcje SOUNDEX i DIFFERENCE pozwalają na odnajdywanie podobieństw fonetycznych, choć – jak pokazują przykłady – najlepiej sprawdzają się one w języku angielskim. W polskich warunkach, gdzie mamy do czynienia z wieloma znakami diakrytycznymi oraz specyficzną fonetyką, wyniki bywają niedokładne lub zaskakujące.
Widzieliśmy, że:
SOUNDEX przypisuje słowom kody fonetyczne, a DIFFERENCE porównuje ich podobieństwo na skali od 0 do 4.
W praktyce trudno ustalić jeden uniwersalny próg – często przyjmuje się 3 lub 4, ale warto traktować to tylko jako wstępne filtrowanie danych.
Normalizacja (np. usuwanie polskich znaków diakrytycznych) znacząco poprawia skuteczność dopasowań i pozwala lepiej wykorzystać dostępne funkcje SQL.
Choć same mechanizmy wbudowane w SQL Server mają swoje ograniczenia, to już na tym etapie można zyskać dużo lepsze wyniki niż przy prostym porównaniu WHERE Nazwa = '...'. W bardziej wymagających scenariuszach warto sięgnąć po dodatkowe techniki fuzzy matching, takie jak Levenshtein czy Damerau-Levenshtein, lub własne reguły biznesowe dostosowane do specyfiki danych.
Najważniejszy wniosek? Nawet podstawowe narzędzia SQL, wzbogacone o prostą normalizację, pozwalają znacząco poprawić jakość porównań i wyszukiwań w bazie danych.


